Data Science Example - Iris dataset.
Fisher’s Iris data base (Fisher, 1936) is perhaps the best known database to be found in the pattern recognition literature. The data set contains 3 classes of 50 instances each, where each class refers to a type of iris plant.
The Iris Dataset contains four features (length and width of sepals and petals) of 50 samples of three species of Iris (Iris setosa, Iris virginica and Iris versicolor). These measures were used to create a linear discriminant model to classify the species.
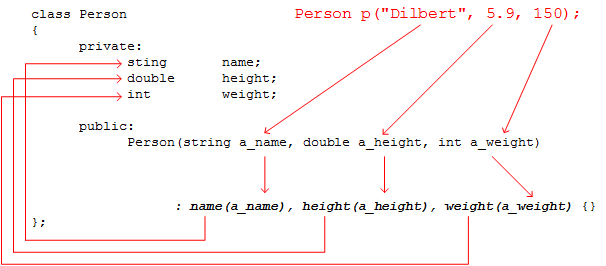
The aim is to classify iris flowers among three species (setosa, versicolor or virginica) from measurements of length and width of sepals and petals. The iris data set contains 3 classes of 50 instances each, where each class refers to a type of iris plant.

The data set contains 3 classes of 50 instances each, where each class refers to a type of iris plant. One class is linearly separable from the other 2; the latter are NOT linearly separable from each other. Predicted attribute: class of iris plant. This is an exceedingly simple domain.

The Iris flower data set or Fisher's Iris data set is a multivariate data set introduced by the British statistician and biologist Ronald Fisher in his 1936 paper The use of multiple measurements in taxonomic problems as an example of linear discriminant analysis.

About the data set. The Iris flower data set or Fisher’s Iris data set is a multivariate data set introduced by the British statistician and biologist Ronald Fisher in his 1936 paper. This is a very famous and widely used dataset by everyone trying to learn machine learning and statistics.

Naive Bayes algorithm using iris dataset. This algorith is based on probabilty, the probability captures the chance that an event will occur in the light of the available evidence. The lower the probability, the less likely the event is to occur. A probability of 0 indicates that the event will definitily not occur.

Luckily the Iris Data Set has evenly distributed class labels, so epsilon will be chosen arbitrarily. For other data sets where class labels are not evenly distributed it is likely that a badly chosen epsilon could affect classification. This will be a likely post for the future, parameter optimization. Some Help, But Not Too Much. Numpy; SciPy.

The iris dataset contains NumPy arrays already. For other dataset, by loading them into NumPy. Features and response should have specific shapes. 150 x 4 for whole dataset. 150 x 1 for examples. 4 x 1 for features. you can convert the matrix accordingly using np.tile (a, (4, 1)), where a is the matrix and (4, 1) is the intended matrix.

There are 465 classification datasets available on data.world. Find open data about classification contributed by thousands of users and organizations across the world.

This data set has points in R 4 describing sepal length, sepal width, petal length, and petal width. In the set there are three species of Iris, i.e., Iris Setosa, Iris Versicolor, and Iris Virginica (see Fig. 1, Fig. 2, and Fig. 3). Each species is represented by 50 points, so the Iris data set has 150 points. Some samples of the data set are.
A new model for iris data set classification based on l inear support vector machine parameter's optimization Zahraa Faiz Hussa in 1, Hind Raad Ibrahee m 2, Mohammad Alsajri 3, Ahmed Hussein.

Do you want to do machine learning using Python, but you’re having trouble getting started? In this post, you will complete your first machine learning project using Python. In this step-by-step tutorial you will: Download and install Python SciPy and get the most useful package for machine learning in Python. Load a dataset and understand it’s structure using statistical summaries and data.